Qos on Rt3200 Have to Apply Again
Every group on HiPerGator (HPG) must have an investment with a respective hardware allocation to be able to do any piece of work on HPG. Each allotment is associated with a scheduler business relationship. Each business relationship has two quality of service (QOS) levels - high-priority investment QOS and a low-priority outburst QOS. The latter allows short-term borrowing of unused resources from other groups' accounts. In turn, each user in a group has a scheduler business relationship association. In the stop, it is this clan which determines which QOSes are available to a particular user. Users with secondary Linux group membership volition have associations with QOSes from their secondary groups.
In summary, each HPG user has scheduler associations with group account based QOSes that decide what resources are available to the users's jobs. These QOSes can exist thought of as pools of computational (CPU cores), retention (RAM), maximum run time (time limit) resources with associated starting priority levels that can be consumed by jobs to run applications according to QOS levels, which we will review beneath.
Contents
- 1 Account and QOS
- one.1 Using the resources from a secondary group
- i.2 See your associations
- i.3 QOS Resource Limits
- 1.4 QOS Time Limits
- one.v CPU cores and Memory (RAM) Resource Apply
- 1.6 GPU Resource Limits
- two Choosing QOS for a Job
- three Examples
- 4 Pending Task Reasons
Account and QOS
Using the resources from a secondary group
Past default, when you submit a chore on HiPerGator, information technology will use the resources from your primary group. You can hands see your primary and secondary groups with the id command:
[agator@login4 ~]$ id uid=12345(agator) gid=12345(gator-group) groups=12345(gator-group),12346(second-group),12347(third-grouping) [agator@login4 ~]$
As shown above, our fictional user agator'due south primary group is gator-group and they too accept secondary groups of 2nd-group and tertiary-group.
To employ the resources of 1 of their secondary groups rather than their master grouping, agator can apply the --account and --qos flags, in the submit script, in the sbatch command or in the boxes in the Open on Demand interface. For example, to use the orangish-group they could:
- In a submit script, add these lines:
#SBATCH --account=2nd-group
#SBATCH --qos=second-group - In the
sbatchcommand:sbatch --business relationship=second-grouping --qos=second-group my_script.sh - Using Open up on Demand:
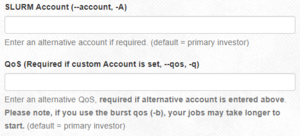
How to gear up account and qos options to use resources from a secondary group in Open on Need
- Note: Jupyterhub can merely use your primary group'south resources and cannot be used for accessing secondary group resources.
- Note: To use a secondary group's Outburst QOS the --business relationship= parameter is withal '2d-grouping', while the --qos= parameter is 'second-grouping-b'. The QOS is different, but the account remains the aforementioned. This may make more sense by viewing the output of the showAssoc command in the See your associations department immediately below.
See your associations
On the command line, you tin can view your SLURM associations with the showAssoc control:
$ showAssoc <username>
Case: $ showAssoc magitz output:
User Business relationship Def Acct Def QOS QOS ------------------ ---------- ---------- --------- ---------------------------------------- magitz zoo6927 ufhpc ufhpc zoo6927,zoo6927-b magitz ufhpc ufhpc ufhpc ufhpc,ufhpc-b magitz soltis ufhpc soltis soltis,soltis-b magitz borum ufhpc borum borum,borum-b
The output shows that the user magitz has 4 account associations and eight dissimilar QOSes. By convention, a user's default account is always the account of their master grouping. Additionally, their default QOS is the investment (high-priority) QOS. If a user does non explicitly asking a specific account and QOS, the user'due south default account and QOS will exist assigned to the task.
If the user magitz wanted to use the borum group'south account - which he has admission by virtue of the borum account association - he would specify the account and the chosen QOS in his batch script as follows:
#SBATCH --account=borum #SBATCH --qos=borum
Or, for the burst QOS:
#SBATCH --account=borum #SBATCH --qos=borum-b
Annotation that both --account and --qos must be specified. Otherwise scheduler volition assume the default ufhpc account is intended, and neither the borum nor borum-b QOSes will exist available to the job. Consequently, scheduler would deny the submission. In addition, you cannot mix and match resource from different allocations.
These sbatch directives tin can also be given as command line arguments to srun. For example:
$ srun --account=borum --qos=borum-b <example_command>
QOS Resource Limits
CPU cores, Retentivity (RAM), GPU accelerators, software licenses, etc. are referred to as Trackable Resources (TRES) by the scheduler. The TRES available in a given QOS are determined by the group's investments and the QOS configuration.
View a trackable resources limits for a QOS:
$ showQos <specified_qos>
Example: $ showQos borum output:
Name Descr GrpTRES GrpCPUs -------------------- ------------------------------ --------------------------------------------- -------- borum borum qos cpu=9,gres/gpu=0,mem=32400M 9
Nosotros can run into that the borum investment QOS has a pool of 9 CPU cores, 32GB of RAM, and no GPUs. This pool of resource is shared amidst all members of the borum grouping.
Similarly, the borum-b> burst QOS resource limits shown by $ showQos borum-b are:
Name Descr GrpTRES GrpCPUs -------------------- ------------------------------ --------------------------------------------- -------- borum-b borum burst qos cpu=81,gres/gpu=0,mem=291600M 81
There are additional base priority and run time limits associated with QOSes. To display them run
$ sacctmgr show qos format="name%-twenty,Description%-30,priority,maxwall" <specified_qos>
Example: $ sacctmgr show qos format="name%-20,Description%-30,priority,maxwall" borum borum-b output:
Proper name Descr Priority MaxWall -------------------- ------------------------------ ---------- ----------- borum borum qos 36000 31-00:00:00 borum-b borum burst qos 900 four-00:00:00
The investment and burst QOS jobs are limited to 31 and 4 twenty-four hours run times, respectively. Additionally, the base priority of a flare-up QOS job is one/40th that of an investment QOS job. It is important to remember that the base priority is but one component of the jobs overall priority and that the priority volition modify over time equally the job waits in the queue.
The flare-up QOS cpu and memory limits are 9 times (9x) those of the investment QOS up to a certain limit and are intended to allow groups to take reward of unused resources brusque periods of time by borrowing resources from other groups.
QOS Time Limits
- Jobs with longer time limits are more difficult to schedule.
- Long fourth dimension limits make system maintenance harder. We have to perform maintenance on the systems (Os updates, security patches, etc.). If the allowable time limits were longer, information technology could brand important maintenance tasks nigh impossible. Of item importance is the power to install security updates on the systems speedily and efficiently. If we cannot install them considering user jobs are running for months at a time, we take to choose to either kill the user jobs or risk security issues on the system, which could bear on all users.
- The longer a job runs, the more likely it is to end prematurely due to random hardware failure.
Thus, if the application allows saving and resuming the analysis information technology is recommended that instead of running jobs for extremely long times, you utilize checkpointing of your jobs so that you tin restart them and run shorter jobs instead.
The 31 day investment QOS time limit on HiPerGator is generous compared to other major institutions. Here are examples we were able to discover.
| Institution | Maximum Runtime |
|---|---|
| New York University | 4 days |
| University of Southern California | 2 weeks for i node, otherwise 1 day |
| PennState | 2 weeks for up to 32 cores (contributors), 4 days for upwardly to 256 cores otherwise |
| UMBC | 5 days |
| TACC: Stampede | 2 days |
| TACC: Lonestar | 1 24-hour interval |
| Princeton: Della | 6 days |
| Princeton: Hecate | 15 days |
| University of Maryland | 14 days |
CPU cores and Memory (RAM) Resource Employ
CPU cores and RAM are allocated to jobs independently as requested in chore scripts. Considerations for selecting how many CPU cores and how much memory to request for a job must take into account the QOS limits based on the group investment, the limitations of the hardware (compute nodes), and the desire to be a good neighbor on a shared resource like HiPerGator to ensure that organization resource are allocated efficiently, used fairly, and everyone has a chance to go their piece of work done without causing negative impacts on work performed by other researchers.
HiPerGator consists of many interconnected servers (compute nodes). The hardware resources of each compute node, including CPU cores, memory, retentivity bandwidth, network bandwidth, and local storage are limited. If whatsoever single 1 of the above resources is fully consumed the remaining unused resources can become effectively wasted, which makes it progressively harder or even incommunicable to achieve the shared goals of Research Computing and the UF Researcher Community stated in a higher place. See the Bachelor Node Features for details on the hardware on compute nodes. Nodes with similar hardware are generally separated into partitions. If the job requires larger nodes or detail hardware make certain to explicitly specify a partition. Instance:
--sectionalization=bigmem
When a job is submitted, if no resources request is provided, the default limits of 1 CPU core, 600MB of retentivity, and a ten minute time limit will be set up on the task by the scheduler. Check the resource request if it's non clear why the chore ended earlier the analysis was washed. Premature exit can be due to the job exceeding the time limit or the awarding using more than retentivity than the request.
Run testing jobs to find out what resource a particular assay needs. To make sure that the analysis is performed successfully without wasting valuable resources yous must specify both the number of CPU cores and the amount of retention needed for the assay in the job script. See Sample SLURM Scripts for examples of specifying CPU core requests depending on the nature of the application running in a job. Use --mem (total job memory on a node) or --mem-per-cpu (per-core retentivity) options to asking retention. Utilize --fourth dimension to set a time limit to an appropriate value within the QOS limit.
As jobs are submitted and the resource under a particular account are consumed the group may reach either the CPU or Memory group limit. The group has consumed all cores in a QOS if the scheduler shows QOSGrpCpuLimit or retentiveness if the scheduler shows QOSGrpMemLimit in the reason a job is pending ('NODELIST(REASON)' column of the squeue control output).
Case:
JOBID Segmentation NAME USER ST Fourth dimension NODES NODELIST(REASON) 123456 bigmem test_job jdoe PD 0:00 one (QOSGrpMemLimit)
Reaching a resource limit of a QOS does not interfere with job submission. Nevertheless, the jobs with this reason will not run and will remain in the pending country until the QOS use falls below the limit.
If the resource asking for submitted chore is incommunicable to satisfy within either the QOS limits or HiPerGator compute node hardware for a particular sectionalisation the scheduler will decline the job submission altogether and return the following error bulletin,
sbatch: error: Batch chore submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
GPU Resource Limits
As per the Scheduler/Job Policy, in that location is no flare-up QOS for GPU jobs.
Choosing QOS for a Job
When choosing between the high-priority investment QOS and the 9x larger low-priority burst QOS, you lot should start by because the overall resource requirements for the job. For smaller allocations the investment QOS may not exist large enough for some jobs, whereas for other smaller jobs the wait fourth dimension in the burst QOS could be too long. In addition, consider the electric current state of the account you are planning to utilise for your task.
To show the condition of any SLURM account as well as the overall usage of HiPerGator resources, utilize the following control from the ufrc surroundings module:
$ slurmInfo
for the primary account or
$ slurmInfo <account>
for another business relationship
Example: $ slurmInfo ufgi:
---------------------------------------------------------------------- Allocation summary: Time Limit Hardware Resources Investment QOS Hours CPU MEM(GB) GPU ---------------------------------------------------------------------- ufgi 744 150 527 0 ---------------------------------------------------------------------- CPU/MEM Usage: Running Pending Full CPU MEM(GB) CPU MEM(GB) CPU MEM(GB) ---------------------------------------------------------------------- Investment (ufgi): 100 280 0 0 100 280 ---------------------------------------------------------------------- HiPerGator Utilization CPU: Used (%) / Total MEM(GB): Used (%) / Total ---------------------------------------------------------------------- Total : 43643 (92%) / 47300 113295500 (57%) / 196328830 ---------------------------------------------------------------------- * Burst QOS uses idle cores at low priority with a four-solar day time limit Run 'slurmInfo -h' to see all bachelor options
The output shows that the investment QOS for the ufgi account is actively used. Since 100 CPU cores out of 150 available are used only 50 cores are bachelor. In the same vein since 280GB out of 527GB in the investment QOS are used 247GB are still available. The ufgi-b burst QOS is unused. Te total HiPerGator employ is 92% of all CPU cores and 57% of all retentivity on compute nodes, which means that there is little available capacity from which burst resources tin be drawn. In this case a job submitted to the ufgi-b QOS would likely accept a long time to start. If the overall utilization was below 80% it would exist easier to start a burst job inside a reasonable amount of fourth dimension. When the HiPerGator load is loftier, or if the burst QOS is actively used, the investment QOS is more advisable for a smaller job.
Examples
A hypothetical group ($GROUP in the examples beneath) has an investment of 42 CPU cores and 148GB of memory. That's the grouping'south then-called soft limit for HiPerGator jobs in the investment qos for upwards to 744 hour fourth dimension limit at high priority. The difficult limit accessible through the so-called burst qos is 9 times that giving a group potentially a total of 10x the invested resources i.east. 420 total CPU cores and 1480GB of total memory with burst qos providing 378 CPU cores and 1330GB of total memory for up to 96 hours at low base priority.
Permit'southward test:
[marvin@gator ~]$ srun --mem=126gb --pty bash -i srun: job 123456 queued and waiting for resources #Looks good, allow's stop the asking with Ctrl+C> ^C srun: Task allocation 123456 has been revoked srun: Force Terminated job 123456
On the other hand, going fifty-fifty 1gb over that limit results in the already encountered job limit error
[marvin@gator ~]$ srun --mem=127gb --pty bash -i srun: mistake: Unable to allocate resources: Job violates bookkeeping/QOS policy (job submit limit, user'due south size and/or fourth dimension limits
At this point the group can try using the 'burst' QOS with
#SBATCH --qos=$Grouping-b
Permit'due south test:
[marvin@gator3 ~]$ srun -p bigmem --mem=400gb --fourth dimension=96:00:00 --qos=$GROUP-b --pty fustigate -i srun: job 123457 queued and waiting for resource #Looks good, let's end with Ctrl+C ^C srun: Job allotment 123457 has been revoked srun: Force Terminated task 123457
However, now there'south the burst qos time limit to consider.
[marvin@gator ~]$ srun --mem=400gb --time=300:00:00 --pty fustigate -i srun: error: Unable to allocate resource: Task violates accounting/QOS policy (chore submit limit, user'due south size and/or time limits
Permit'southward reduce the time limit to what burst qos supports and try once again.
[marvin@gator ~]$ srun --mem=400gb --fourth dimension=96:00:00 --pty fustigate -i srun: job 123458 queued and waiting for resources #Looks good, allow's cease with Ctrl+C ^C srun: Job allocation 123458 has been revoked srun: Forcefulness Terminated job
Pending Job Reasons
To reiterate, the following Reasons tin can be seen in the NODELIST(REASON) cavalcade of the squeue command when the group reaches the resource limit for a QOS:
- QOSGrpCpuLimit
All CPU cores available for the listed business relationship within the respective QOS are in use.
- QOSGrpMemLimit
All memory available for the listed business relationship within the respective QOS as described in the previous section is in use.
- Notation
In one case information technology has marked any jobs in the grouping's listing of awaiting jobs with a reason of QOSGrpCpuLimit or QOSGrpMemLimit, SLURM may not evaluate other jobs and they may but be listed with the Priority reason lawmaking.
Source: https://help.rc.ufl.edu/doc/Account_and_QOS_limits_under_SLURM
0 Response to "Qos on Rt3200 Have to Apply Again"
Post a Comment